About the Project
This project addresses the critical issue of employee attrition using Data Science and Analytics. By analyzing IBM HR datasets, we identify patterns leading to attrition and predict potential cases, enabling proactive retention measures.
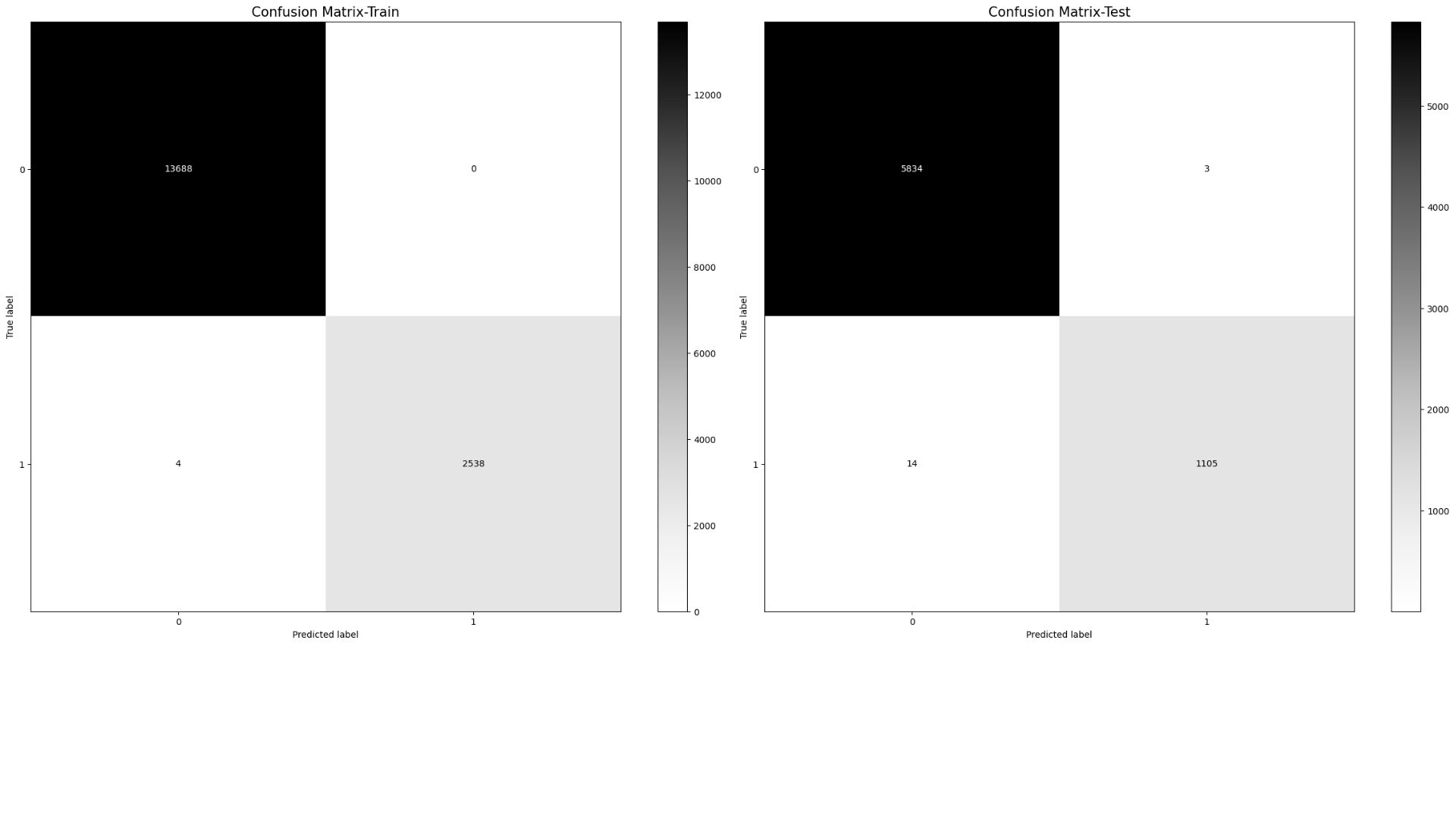
The solution achieves 99.8% accuracy in predicting attrition using advanced machine learning techniques.
Project Goals
- Analyze employee profiles and identify attrition patterns
- Build predictive models to flag at-risk employees
- Provide actionable insights for HR decision-making
- Compare performance of multiple ML algorithms
Dataset
IBM HR Analytics Dataset with 24,000 employee records containing:
- Categorical Features: Department, JobRole, OverTime, BusinessTravel, etc.
- Numerical Features: Age, MonthlyIncome, JobSatisfaction, YearsAtCompany, etc.
- Target Variable: Attrition (Yes/No)
Methodology
Data Preprocessing
- Exploratory Data Analysis with visualization
- Handling missing values and feature engineering
- Label encoding and one-hot encoding for categorical variables
- SMOTE for handling class imbalance
Machine Learning Models
- Evaluated 8+ algorithms including Logistic Regression, Random Forest, and XGBoost
- Feature selection using RFE and SequentialFeatureSelector
- Hyperparameter tuning for optimal performance
Results
- Train Accuracy: 99.98%
- Test Accuracy: 99.81%
- ROC-AUC Score: 0.99
XGBoost outperformed other models with near-perfect accuracy in identifying attrition cases.